
本稿ではファイル処理の際にsplit関数で要素を抽出する方法を紹介します。
split関数で要素を抽出する
ファイルの中身を読み込むときに、区切り文字の空白の間隔がバラバラだったりすると空文字列が無秩序にリスト化されるなどして処理に手間がかかることがあります。例えば次のようなファイルの場合。
702
-OEChem-09302102203D
9 8 0 0 0 0 0 0 0999 V2000
-1.1712 0.2997 0.0000 O 0 0 0 0 0 0 0 0 0 0 0 0
-0.0463 -0.5665 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0
1.2175 0.2668 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0
-0.0958 -1.2120 0.8819 H 0 0 0 0 0 0 0 0 0 0 0 0
-0.0952 -1.1938 -0.8946 H 0 0 0 0 0 0 0 0 0 0 0 0
2.1050 -0.3720 -0.0177 H 0 0 0 0 0 0 0 0 0 0 0 0
1.2426 0.9307 -0.8704 H 0 0 0 0 0 0 0 0 0 0 0 0
1.2616 0.9052 0.8886 H 0 0 0 0 0 0 0 0 0 0 0 0
-1.1291 0.8364 0.8099 H 0 0 0 0 0 0 0 0 0 0 0 0
1 2 1 0 0 0 0
1 9 1 0 0 0 0
2 3 1 0 0 0 0
2 4 1 0 0 0 0
2 5 1 0 0 0 0
3 6 1 0 0 0 0
3 7 1 0 0 0 0
3 8 1 0 0 0 0
M END
これはPubchemというアメリカ国立衛生研究所の化合物データベースから取得したエタノールの分子構造に関するSDF形式のデータです。区切り文字の半角スペースの数が行によって異なるため、このようなファイルの処理ではsplit関数が活躍します。今回は例としてこのSDF形式のファイルの数値を読み込んでみましょう。
SDF形式の中身は以下のような構造になっています。
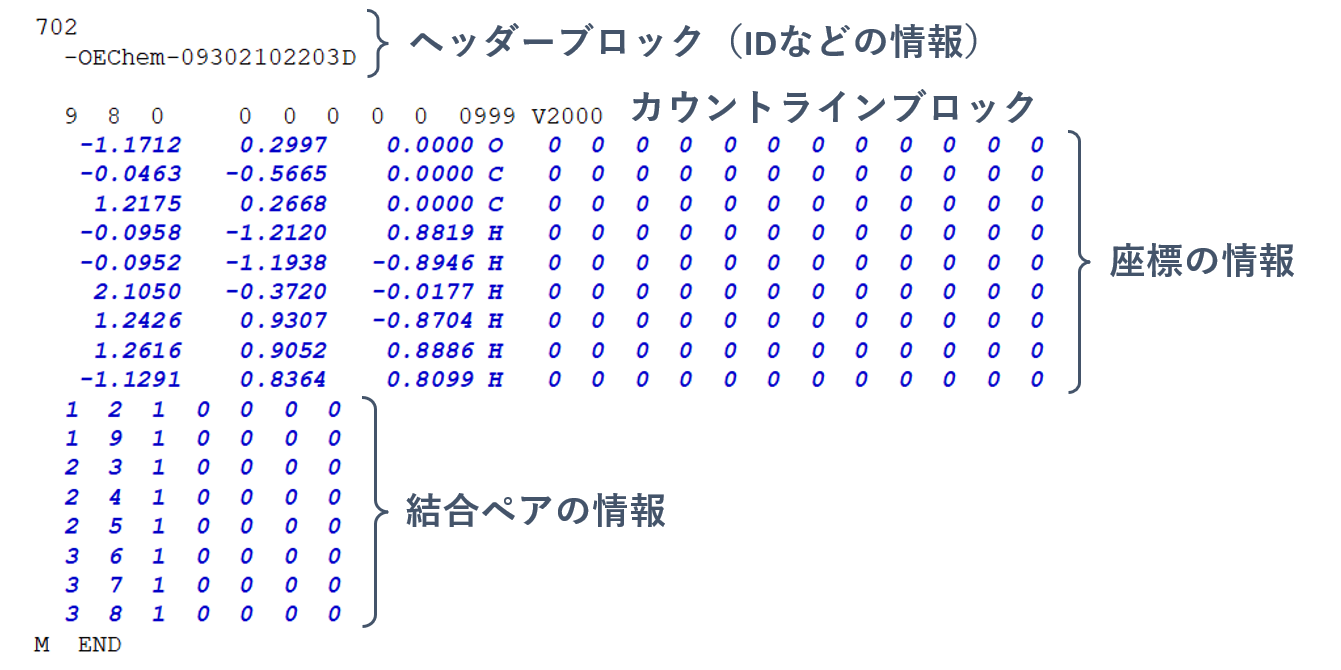
ここでは座標の情報を読み取ることにします。split関数は引数に区切り文字を指定できますが、特に指定しない場合は複数の空白があってもそれぞれの要素を取得することができます。
# sdfファイルのパス
input_file = "Ethanol.sdf"
# xyz座標の取得
atomnum = 0; atomname = []; atomcoord = []
with open(input_file, encoding='utf-8') as f:
while True: # 読み込める行が無くなるまで繰り返す
line = f.readline() # ファイル f を1行ずつ読み込んでいく
elem = line.split() # 読み込んだ行を要素に分割する
if len(elem) > 10: # 要素数が10を超える行のみ処理する
atomname.append((elem[3])) # 4列目の要素は元素記号
atomcoord.append([float(elem[0]), float(elem[1]), float(elem[2])]) # 1~3列目の要素はx,y,z座標
atomnum += 1 # 原子数をカウント
if not line: # 読み込める行が無くなったら break
break
# 取得データの確認
print(atomnum)
print(atomname)
print(atomcoord)
重要なのは「f.readline()」で取得した行に対してsplit()を作用させて要素に分割している部分です。これでEthanol.sdfの5行目から13行目までの各要素を取得しています。これを実行すると以下のようにデータが出力されます。
9 ['O', 'C', 'C', 'H', 'H', 'H', 'H', 'H', 'H'] [[-1.1712, 0.2997, 0.0], [-0.0463, -0.5665, 0.0], [1.2175, 0.2668, 0.0], [-0.0958, -1.212, 0.8819], [-0.0952, -1.1938, -0.8946], [2.105, -0.372, -0.0177], [1.2426, 0.9307, -0.8704], [1.2616, 0.9052, 0.8886], [-1.1291, 0.8364, 0.8099]]
※この程度のデータであればExcelなどでもすぐに処理できますが、ファイル数が数百~数千以上になるとプログラムを使わなければ現実的な時間で終わりません。そのような時にささっとPythonのプログラムが書けるととても便利です。
split関数の区切り文字を指定する
「複数の空白を含む行の要素を取得する」という目的にはあまり合致しませんが、split関数の区切り文字を指定する方法についても簡単に触れておきます。
基本的にはsplit()の括弧内に区切り文字を指定するだけです。例えば「20世紀最大の画家」と名高いスペインの画家パブロ・ピカソの本名は
「パブロ・ディエゴ・ホセ・フランシスコ・デ・パウラ・ホアン・ネポムセーノ・マリア・デ・ロス・レメディオス・クリスピーン・クリスピアーノ・デ・ラ・サンティシマ・トリニダード・ルイス・イ・ピカソ」
…というらしいですが、これを単語に分割するには次のようにします。
# coding: UTF-8
name = "パブロ・ディエゴ・ホセ・フランシスコ・デ・パウラ・ホアン・ネポムセーノ・マリア・デ・ロス・レメディオス・クリスピーン・クリスピアーノ・デ・ラ・サンティシマ・トリニダード・ルイス・イ・ピカソ"
print(name.split("・"))
# ['パブロ', 'ディエゴ', 'ホセ', 'フランシスコ', 'デ', 'パウラ', 'ホアン', 'ネポムセーノ', 'マリア', 'デ', 'ロス', 'レメディオス', 'クリスピーン', 'クリスピアーノ', 'デ', 'ラ', 'サンティシマ', 'トリニダード', 'ルイス', 'イ', 'ピカソ']
区切り文字には英数字だけでなく日本語も指定可能です。
※split関数は文字列に対してのみ実行可能です。リスト型オブジェクト丸ごとに適用するのは無理なので、for文などを使って各要素である文字列に一つ一つ適用します。
※余談ですが、タイの首都バンコクの正式名称も長いことで有名ですね。
複数の区切り文字を指定するには
複数の区切り文字を指定するには正規表現を扱うreモジュールを利用するのが便利です。
例えば、日本国憲法の前文を句読点で分割するには次のようにします。
# coding: UTF-8
import re
Preamble = "日本国民は、正当に選挙された国会における代表者を通じて行動し、われらとわれらの子孫のために、諸国民との協和による成果と、わが国全土にわたつて自由のもたらす恵沢を確保し、政府の行為によつて再び戦争の惨禍が起ることのないやうにすることを決意し、ここに主権が国民に存することを宣言し、この憲法を確定する。そもそも国政は、国民の厳粛な信託によるものであつて、その権威は国民に由来し、その権力は国民の代表者がこれを行使し、その福利は国民がこれを享受する。これは人類普遍の原理であり、この憲法は、かかる原理に基くものである。われらは、これに反する一切の憲法、法令及び詔勅を排除する。日本国民は、恒久の平和を念願し、人間相互の関係を支配する崇高な理想を深く自覚するのであつて、平和を愛する諸国民の公正と信義に信頼して、われらの安全と生存を保持しようと決意した。われらは、平和を維持し、専制と隷従、圧迫と偏狭を地上から永遠に除去しようと努めている国際社会において、名誉ある地位を占めたいと思ふ。われらは、全世界の国民が、ひとしく恐怖と欠乏から免かれ、平和のうちに生存する権利を有することを確認する。われらは、いづれの国家も、自国のことのみに専念して他国を無視してはならないのであつて、政治道徳の法則は、普遍的なものであり、この法則に従ふことは、自国の主権を維持し、他国と対等関係に立たうとする各国の責務であると信ずる。日本国民は、国家の名誉にかけ、全力をあげてこの崇高な理想と目的を達成することを誓ふ。"
print(re.split("[、。]", Preamble))
# ['日本国民は', '正当に選挙された国会における代表者を通じて行動し', 'われらとわれらの子孫のために', '諸国民との協和による成果と', 'わが国全土にわたつて自由のもたらす恵沢を確保し', '政府の行為によつて再び戦争の惨禍が起ることのないやうにすることを決意し', 'ここに主権が国民に存することを宣言し', 'この憲法を確定する', 'そもそも国政は', '国民の厳粛な信託によるものであつて', 'その権威は国民に由来し', 'その権力は国民の代表者がこれを行使し', 'その福利は国民がこれを享受する', 'これは人類普遍の原理であり', 'この憲法は', 'かかる原理に基くものである', 'われらは', 'これに反する一切の憲法', '法令及び詔勅を排除する', '日本国民は', '恒久の平和を念願し', '人間相互の関係を支配する崇高な理想を深く自覚するのであつて', '平和を愛する諸国民の公正と信義に信頼して', 'われらの安全と生存を保持しようと決意した', 'われらは', '平和を維持し', '専制と隷従', '圧迫と偏狭を地上から永遠に除去しようと努めている国際社会において', '名誉ある地位を占めたいと思ふ', 'われらは', '全世界の国民が', 'ひとしく恐怖と欠乏から免かれ', '平和のうちに生存する権利を有することを確認する', 'われらは', 'いづれの国家も', '自国のことのみに専念して他国を無視してはならないのであつて', '政治道徳の法則は', '普遍的なものであり', 'この法則に従ふことは', '自国の主権を維持し', '他国と対等関係に立たうとする各国の責務であると信ずる', '日本国民は', '国家の名誉にかけ', '全力をあげてこの崇高な理想と目的を達成することを誓ふ', '']
re.split()関数には「区切り文字、文字列」の順に引数を与えて下さい。
csvファイルを読み込むには
split関数は便利ですが、カンマと空白/タブ区切りが入り混じったcsvファイルの読み取りは少し苦手です。次のような「価格」を含むファイルはその典型的な例です。
"年月","始値","高値","安値","終値" "2020/01","23,204","24,083","22,977","23,205" "2020/02","22,971","23,873","21,142","21,142" "2020/03","21,344","21,344","16,552","18,917" "2020/04","18,065","20,193","17,818","20,193" "2020/05","19,619","21,916","19,619","21,877" "2020/06","22,062","23,178","21,530","22,288" "2020/07","22,121","22,945","21,710","21,710" "2020/08","22,195","23,296","22,195","23,139" "2020/09","23,138","23,559","23,032","23,185" "2020/10","23,185","23,671","22,977","22,977" "2020/11","23,295","26,644","23,295","26,433" "2020/12","26,787","27,568","26,436","27,444" "2021/01","27,258","28,822","27,055","27,663" "2021/02","28,091","30,467","28,091","28,966" "2021/03","29,663","30,216","28,405","29,178" "2021/04","29,388","30,089","28,508","28,812" "2021/05","29,331","29,518","27,448","28,860" "2021/06","28,814","29,441","28,010","28,791" "2021/07","28,707","28,783","27,283","27,283" "2021/08","27,781","28,089","27,013","28,089" "2021/09","28,451","30,670","28,451","29,452"
これは2020年1月~2021年9月における日経平均株価の四本値の月次推移をcsv形式にしたものです。split関数の区切り文字を指定せずにそのまま読み込むと、1行が丸ごと要素になったリストが得られます。
input_file = "日経平均.csv"
data = []
with open(input_file, encoding='utf-8') as f:
while True: # 読み込める行が無くなるまで繰り返す
line = f.readline() # ファイル f を1行ずつ読み込んでいく
elem = line.split() # 読み込んだ行を要素に分割する
data.append(elem) # 月ごとの数値リストをリストに追加
if not line: # 読み込める行が無くなったら break
break
# 取得データの確認
for i in range(22):
print(data[i])
# ['"年月","始値","高値","安値","終値"']
# ['"2020/01","23,204","24,083","22,977","23,205"']
# ['"2020/02","22,971","23,873","21,142","21,142"']
# ...
# ['"2021/08","27,781","28,089","27,013","28,089"']
# ['"2021/09","28,451","30,670","28,451","29,452"']
かといってsplit関数の区切り文字にカンマを指定すると、要素を区切るカンマと価格の3桁区切りのカンマの区別ができません。実際に実行すると要素がめちゃくちゃになってしまいます。
input_file = "日経平均.csv"
data = []
with open(input_file, encoding='utf-8') as f:
while True: # 読み込める行が無くなるまで繰り返す
line = f.readline() # ファイル f を1行ずつ読み込んでいく
elem = line.split(",") # 読み込んだ行を要素に分割する
data.append(elem) # 月ごとの数値リストをリストに追加
if not line: # 読み込める行が無くなったら break
break
# 取得データの確認
for i in range(22):
print(data[i])
# ['"年月"', '"始値"', '"高値"', '"安値"', '"終値"\n']
# ['"2020/01"', '"23', '204"', '"24', '083"', '"22', '977"', '"23', '205"\n']
# ['"2020/02"', '"22', '971"', '"23', '873"', '"21', '142"', '"21', '142"\n']
# ...
# ['"2021/08"', '"27', '781"', '"28', '089"', '"27', '013"', '"28', '089"\n']
# ['"2021/09"', '"28', '451"', '"30', '670"', '"28', '451"', '"29', '452"\n']
解決方法として、このようなケースに手っ取り早く対処するためには、csvモジュールやpandasライブラリを利用するのが簡単です。例えば、pandasを使うと次のようにたった3行のコードで完結します。
import pandas as pd
df = pd.read_csv('日経平均.csv', header=0)
print(df)
↓
年月 始値 高値 安値 終値 0 2020/01 23,204 24,083 22,977 23,205 1 2020/02 22,971 23,873 21,142 21,142 2 2020/03 21,344 21,344 16,552 18,917 3 2020/04 18,065 20,193 17,818 20,193 4 2020/05 19,619 21,916 19,619 21,877 5 2020/06 22,062 23,178 21,530 22,288 6 2020/07 22,121 22,945 21,710 21,710 7 2020/08 22,195 23,296 22,195 23,139 8 2020/09 23,138 23,559 23,032 23,185 9 2020/10 23,185 23,671 22,977 22,977 10 2020/11 23,295 26,644 23,295 26,433 11 2020/12 26,787 27,568 26,436 27,444 12 2021/01 27,258 28,822 27,055 27,663 13 2021/02 28,091 30,467 28,091 28,966 14 2021/03 29,663 30,216 28,405 29,178 15 2021/04 29,388 30,089 28,508 28,812 16 2021/05 29,331 29,518 27,448 28,860 17 2021/06 28,814 29,441 28,010 28,791 18 2021/07 28,707 28,783 27,283 27,283 19 2021/08 27,781 28,089 27,013 28,089 20 2021/09 28,451 30,670 28,451 29,452
csvファイルの取り扱いについては「csvファイルの処理」のページも参考にして下さい。